Use Your Business Data with OpenAI GPT via Azure and Cognitive Search
Azure OpenAI Service and Cognitive Search make it incredibly easy to interact with unstructured data like PDF files.


Azure OpenAI Services brings enterprise-level security and controls, allowing companies to integrate with LLMs within their existing cloud environment. In this post, I will show you how to chat with PDF files using Azure OpenAI and Cognitive Search, using Microsoft's great React-based front-end.
Although stopping short of being able to fine-tune OpenAI's models, this service delivers surprisingly good results. My chatbot had no problems analyzing multiple 10-Q documents, spotting trends across them in time, and comparing results to benchmarks.
Introduction
As a prerequisite, you will need an Azure subscription, and you will need to submit a registration form for OpenAI Service. It only took me a few hours for it to get approved.
We'll use the ChatGPT + Enterprise data with Azure OpenAI and Cognitive Search project as a starting point.
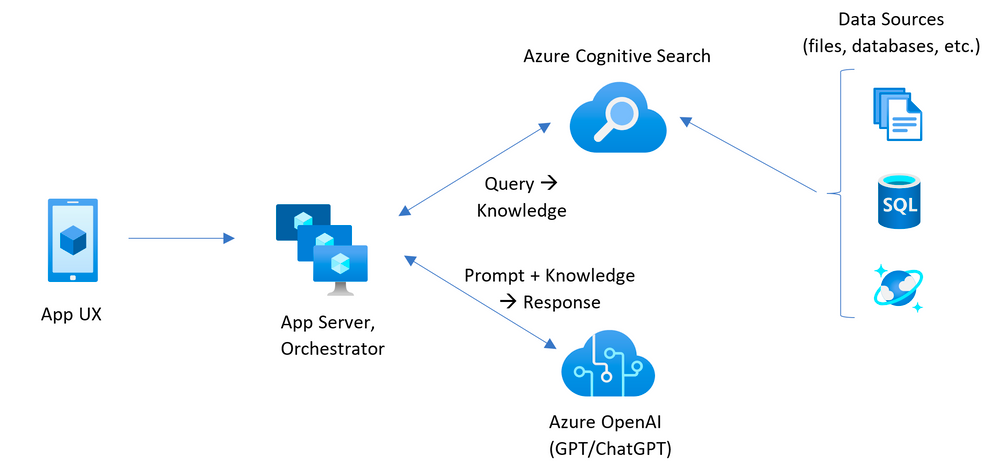
The flow is familiar to those who have used Pinecone or a similar vector for prompt embedding. OpenAI prompt length is limited, so instead of putting the entire dataset in the prompt, the idea is to pull in the bits of information relevant to the current conversation. Unlike Pinecone, however, this approach does not use vector embeddings and relies purely on text.
Azure Search Services stores the indexed and chunked data. It's fast, and the test project has a handy script for loading PDFs.
Before sending the prompt to OpenAI, the app pulls out keywords and queries Cognitive Search for relevant chunks of text and embeds them at the front of the prompt. This simple approach is surprisingly effective.
Loading Data
You can train the project on any dataset; just put the files in the data folder. You can always rerun the data processor with: /scripts/prepdocs.sh.
Setting up the project
Initialize the project:
- In the terminal, create a new folder called
azure-search-openai-demoand switch to it - Run
azd auth login - Run
azd init -t azure-search-openai-demo - Run
azd upto launch the project
If you want to specify an existing resource group, you use azd env set AZURE_OPENAI_RESOURCE_GROUP {name}.
The project will take a few minutes to initialize all its services. Once OpenAI and Cognitive Search services are created, you can run the project locally. Go into the app directory and run either ./start.ps1 (Windows) or ./start.sh (Mac and Linux).
The local server will be running on http://127.0.0.1:5000; navigate to it in your browser. The project comes with a nice React front for interacting with your chat.
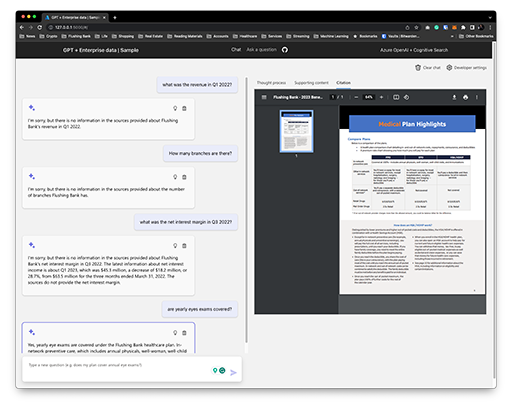
Two Models
The app has two modes: a Q&A mode that uses text-davinci-003 and a chat one that uses gpt-35-turbo. Although similar, they have their differences.
text-davinci-003 performs slightly better than GPT-3.5 Turbo with k-shot examples, and it produces more concise responses than GPT-3.5 Turbo, which may be preferable for certain use cases. It is less accurate with 0-shot falsification and sentiment analysis.
gpt-35-turbo produces longer responses and performs slightly better at math tasks.
I tested the two side by side, and once the prompt was dialed in, they produced similar results on my dataset of business PDF files. With some prompt tweaking, the Chat functionality worked, as well as Q&A on complex queries.
Prompt Tweaks
To get the best results, I found it helpful that the model uses its own knowledge to supplement what it finds in your dataset.
To do that, I added the following:
If the question is broad, combine information from the sources below with your general knowledge.
To make citations look nicer, I added the following:
If the question is broad, combine information from the sources below with your general knowledge.
This will always insert a citation after the sentence without repeating the source.
Finally, because the citation mechanism uses [] brackets, it breaks the replaceable text that ChatGPT sends when composing emails. To fix that, I added the following:
When outputting replaceable text, you must use parenthesis instead of square brackets, e.g. use (NAME) not [NAME], use (FIRST_NAME) not [FIRST_NAME], and use (DATE) not [DATE].
Conclusion
Even in its current nascent form, Azure OpenAI and Cognitive Search work much better than, say, SharePoint search. Loading HR data into the system could help speed onboarding and make it easier for folks to find stuff in vast swaths of company documentation.
We are seeing the early inklings of something powerful and transformational. Once models can train on business data, they will, over time, codify the business processes, handling automation and orchestration.
I have no doubt that with time, Large Language Models will act as general-purpose computing platforms, taking high-level natural language instructions instead of programming code.