LLMs Were Just the Warm-Up. AI's Next Revolution is World Models
While today's Large Language Models learn statistical patterns from text, World Models are designed to understand the underlying physics and causal relationships of the real world. We make a case for World Models and look at cutting edge research from Meta, NVIDIA and Google.


"We're never going to get to human-level intelligence by just training on text."
- Yann LeCun, Chief AI Scientist, Meta
Just as large language models (LLMs) initiated a new era by mastering language, World Foundation Models (WFMs) are driving the next great shift by focusing on reality itself. They move beyond text to create internal representations of how the physical world works, giving machines a human-like ability to understand, predict, and interact intelligently with their surroundings.
Unlike LLMs, which master the statistical patterns of human text and images, a world model is an AI that builds an internal, predictive simulation of how its environment functions.
Imagine you're about to catch a ball. You don't consciously solve complex physics equations, but your brain has an intuitive internal model of how the world works. It predicts the ball's trajectory based on its current speed, spin, and the effects of gravity, allowing you to position your hands for the catch. This internal simulation is the essence of a world model.
An LLM, like GPT-5 knows from its training data that if you drop an apple, it falls. It can write a story about it, explain the concept of gravity, and even write code to simulate it. However, it doesn't possess an intrinsic, learned model of physics itself. A world model, on the other hand, learns the rules of falling by watching countless examples. It learns the rules, dynamics, and cause-and-effect relationships from observation (often video or other sensory data).
| LLM | World Model | |
|---|---|---|
| Training data | Text (billions of tokens) | Sensory data, typically video, but also other environmental inputs |
| Objective | Predict next token in text | Predict next state in an environment |
| Representation | Latent knowledge of language & text-based world | Causal, spatial, and temporal dynamics of a world |
| Use cases | Chat, writing, reasoning, coding | Robotics, autonomous agents, planning |
| Grounding | Indirect (through text) | Direct (through experience) |
Once trained, the AI can use this model to "dream" or simulate possible future scenarios without having to experience them in the real world. This allows it to plan, explore strategies, and learn much more efficiently.
Limits of Language
The debate over whether Large Language Models truly reason or merely pattern-match their training data remains divisive. Yet one thing is indisputable: understanding built solely on human-written text cannot capture the full richness of reality.
Language is an incredibly efficient compression algorithm. It allows us to package the complexities of human experience and transmit them over the low-bandwidth connection of our voice. We can describe everything from scientific theories to deep emotions with remarkable precision. But this system has a critical dependency: a shared understanding of the physical world.
You understand ‘heavy’ not just from its dictionary definition, but from the experience of trying to lift something you couldn’t. What this reveals is the inherent limitation of an AI that has only read the archive of human text. It has learned to master the compressed file but lacks the embodied experience needed to fully decompress it. This is the chasm that separates linguistic competence from genuine, grounded understanding.
A Case for Sensory Data
The training runs for today's LLM models are exercises in extreme scale, consuming hundreds of terabytes of data and planetary-scale computation. Yet, when we benchmark this against the data processing capacity of a single human child, the comparison becomes humbling and reveals a profound data gap.
Consider this: by the time a child reaches their fifth birthday, their brain has already processed a volume of sensory information that rivals the entire text corpus used to train a leading large language model. A continuous, high-bandwidth stream of reality—terabytes of visual input seamlessly integrated with sound, touch, and the dynamic context of the physical world.
We hear impressive figures, such as vision LLMs trained on billions of image-text pairs. While a vast number, this carefully curated dataset is roughly equivalent to just a few weeks of the rich, multi-sensory input a human experiences. It’s also just a series of static snapshots, not a lived experience.
What this reveals is a fundamental difference in the nature of learning. An AI model today learns what a "cat" is from a vast collection of pixel-labeled examples. A child learns by watching it move, hearing it purr, feeling its fur, and understanding its place in the complex system of a home. Their understanding is fused, embodied, and continuous. This isn't just a matter of collecting more data; it's a recognition that our current datasets are a low-resolution facsimile of reality. Bridging this chasm between curated information and lived experience is the next great challenge in the quest for general intelligence.
World Models

World Models are best conceptualized as falling along a continuum of capabilities rather than fitting into a strict definitional framework. Several core dimensions have been identified by researchers as fundamental to world modeling capabilities:
- Physical Understanding: It develops an intuitive grasp of real-world physics, understanding the dynamics of objects and the relationship between cause and effect.
- Predictive: It can forecast future outcomes by running internal simulations of "what if" scenarios.
- Adaptive Learning: It actively builds and refines a mental map of its environment, continuously updating its internal model through real-world interaction
- Planning & Control: It uses its predictions of future outcomes to plan and execute the best course of action to achieve its goals.
This brings us to a fundamental difference in design philosophy compared to large language models. Today's leading LLMs are built almost exclusively on a singular design: the transformer architecture.
Building a world model, however, is a more complex, multi-faceted challenge. It requires a hybrid approach, elegantly composing different types of neural networks: generative architectures to learn rich representations, sequential models to understand time and dynamics, and spatial models to map the structure of an environment.
Leading Industry Initiatives
Building a world model isn't just about making an existing architecture bigger, as it was for LLMs. The real challenge lies in designing entirely new cognitive architectures. This move away from a single, monolithic structure to a composite one is opening up a new world of design possibilities.
Let's examine how this is being done in practice by looking at three leading-edge approaches from Meta, Google, and NVIDIA, each taking a unique approach.
Meta V-JEPA 2
Meta is pursuing a fundamentally different approach to AI with its V-JEPA architecture, designed to overcome what Chief AI Scientist Yann LeCun views as the "technological dead end" of Large Language Models. Instead of focusing on low-level details, V-JEPA attempts to model causal relationships between objects and develop common sense without relying on language. A key advantage of this architecture is its ability to learn through self-supervised video prediction, eliminating the need for any human involvement in the training process.
Rather than attempting to predict "What will the next frame look like?", JEPA approaches the problem by asking, "What will the abstract representation of the next frame be?". This approach compels the model to develop a high-level, semantic comprehension of the world, prioritizing the learning of predictable dynamics over surface-level textures.
The encoder and predictor are first pre-trained on natural videos to build a general understanding of the world. A second phase involves post-training with a smaller amount of robot data to enable practical applications like planning.
The viability of this strategy is demonstrated by the latest 1.2 billion-parameter V-JEPA 2 model. Trained on over a million hours of video, it achieves 85% – 95% accurate prediction and allows for advanced applications like zero-shot robot control in unfamiliar settings, marking a significant advance in video-based world modeling.
NVIDIA Cosmos
NVIDIA Isaac GR00T N1 is humanoid robot foundation model, designed to accelerate development across the entire robotics industry.
For NVIDIA, the next frontier for AI is its application in robotics, autonomous vehicles, and other embodied agents that interact with the physical environment. CEO Jensen Huang has articulated a clear vision where "everything that moves will one day be robotic." To achieve this, AI needs to go beyond processing text and images; it must grasp the nuances of physics, cause and effect, and the unstructured nature of the real world. (Source: NVIDIA)
This is the context for NVIDIA's Cosmos, a platform built around several WFMs. Think of it not as a single product, but as a foundational stack for creating generative digital twins of our world—dynamic, interactive simulations where embodied AI can be trained at scale. By training these large-scale neural networks on vast datasets of real-world and synthetic video, NVIDIA is creating a system that can bypass the traditional bottleneck of physical data collection.
The Cosmos platform is built on three core pillars, each a distinct generative model:
- Cosmos Transfer: This is the on-ramp from reality into the simulation. It ingests complex sensor data—from cameras or LiDAR—and generates a photorealistic, dynamic virtual environment. It’s the critical bridge that allows the digital twin to accurately reflect the state of the physical world.
- Cosmos Predict: This is the forward-looking oracle. It takes the current state of the simulation and generates a sequence of physically plausible futures. This gives an AI the capacity for foresight, allowing it to anticipate outcomes and plan multiple steps ahead.
- Cosmos Reason: This is the causal reasoning engine. It provides the AI with a deeper, more fundamental understanding of cause and effect governed by the laws of physics, space, and time. This model serves as the core planner, enabling an agent to reason about the consequences of its actions and formulate intelligent strategies.
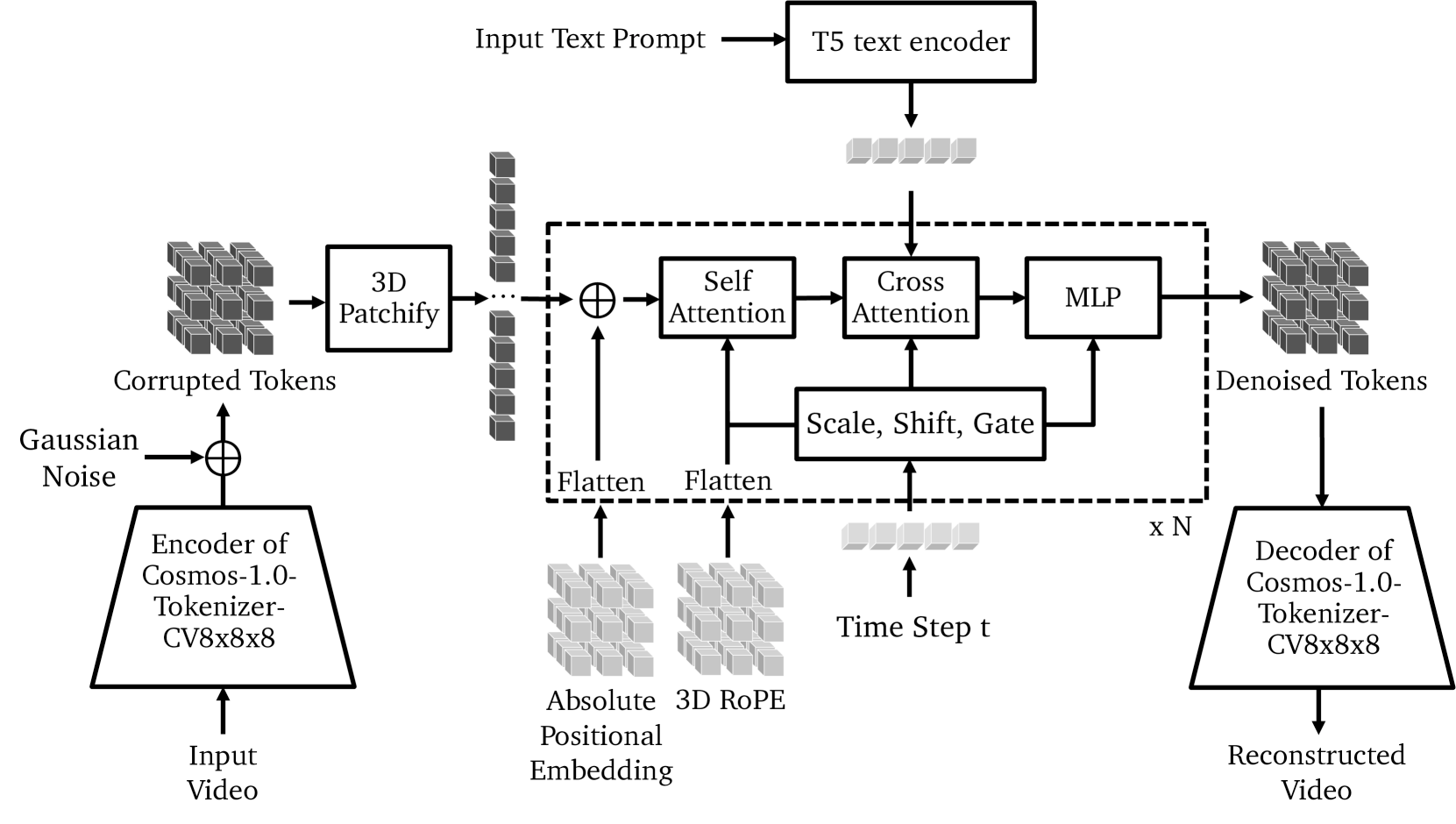
Google Genie 3
Traditionally, creating an interactive world, whether for a game or a simulation, is a meticulous process. Developers must manually build 3D models, create textures, design environments, and then program a physics engine to dictate how every object interacts.
Genie circumvents this entire workflow. It operates as a generative interactive environment. By analyzing hundreds of thousands of hours of gameplay videos, it has learned the underlying rules of motion and cause-and-effect directly from pixels.
| Capability | Description |
|---|---|
| Prompt-Based Generation | Users can provide text prompts (e.g., "a snowy mountain village") or image prompts to generate new environments. |
| Novel Image Understanding | The model can generate worlds based on images it has never seen before, including real-world photographs and sketches. |
| Real-time Interactivity | Genie generates dynamic worlds that can be navigated in real time, allowing for real-time interaction with the environment. |
| World Memory | Genie's generated worlds possess memory, allowing for consistent interactions and the persistence of user actions (e.g., painting on a wall) over time. |
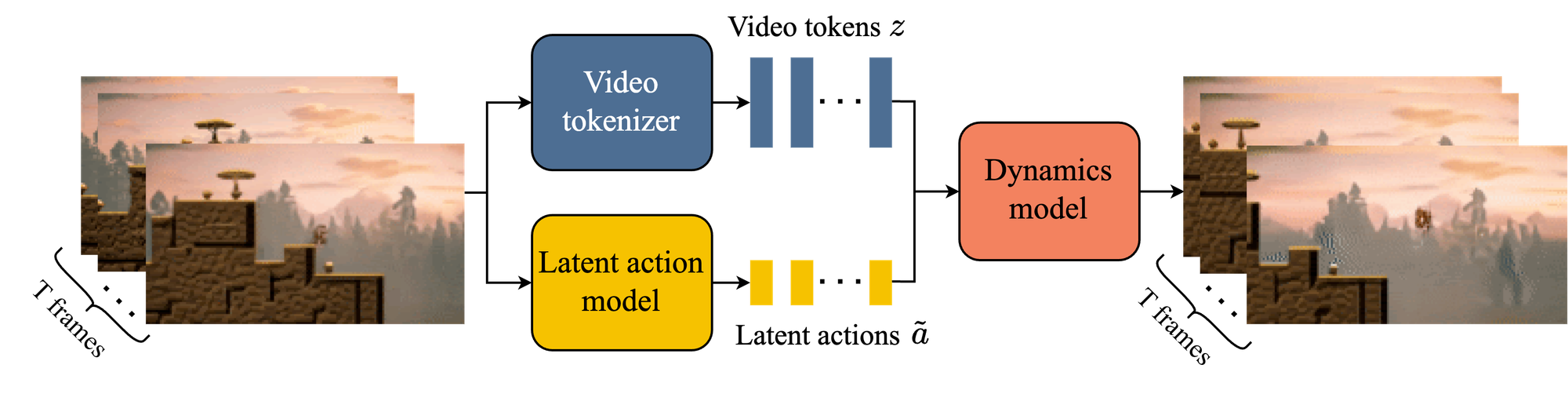
While nascent, Genie hints at a new computational primitive: the on-demand generation of interactive worlds. This capability could radically compress the value chain across industries. Gaming could see infinite, bespoke worlds spun from a sketch; film could move towards truly interactive narratives and crucially, this offers a powerful simulation substrate to accelerate robotics training at an exponential scale.
Conclusion
Current Large Language Models are primarily limited to learning statistical correlations from massive text datasets. A World Model moves beyond this by capturing the causal relationships and underlying physics of an environment. This allows an AI to understand the why behind observed patterns, rather than just the what.
The potential benefits and uses for World Models are immense. Take robotics as an example: even after decades of deployment and extensive use in manufacturing, today's robots are still restricted to performing individual, hard-coded tasks in highly controlled environments. An AI with a grasp of real-world physics and dynamics unlocks the potential for adaptive, general-purpose machines that can finally leave the cage and navigate the unpredictability of our world.
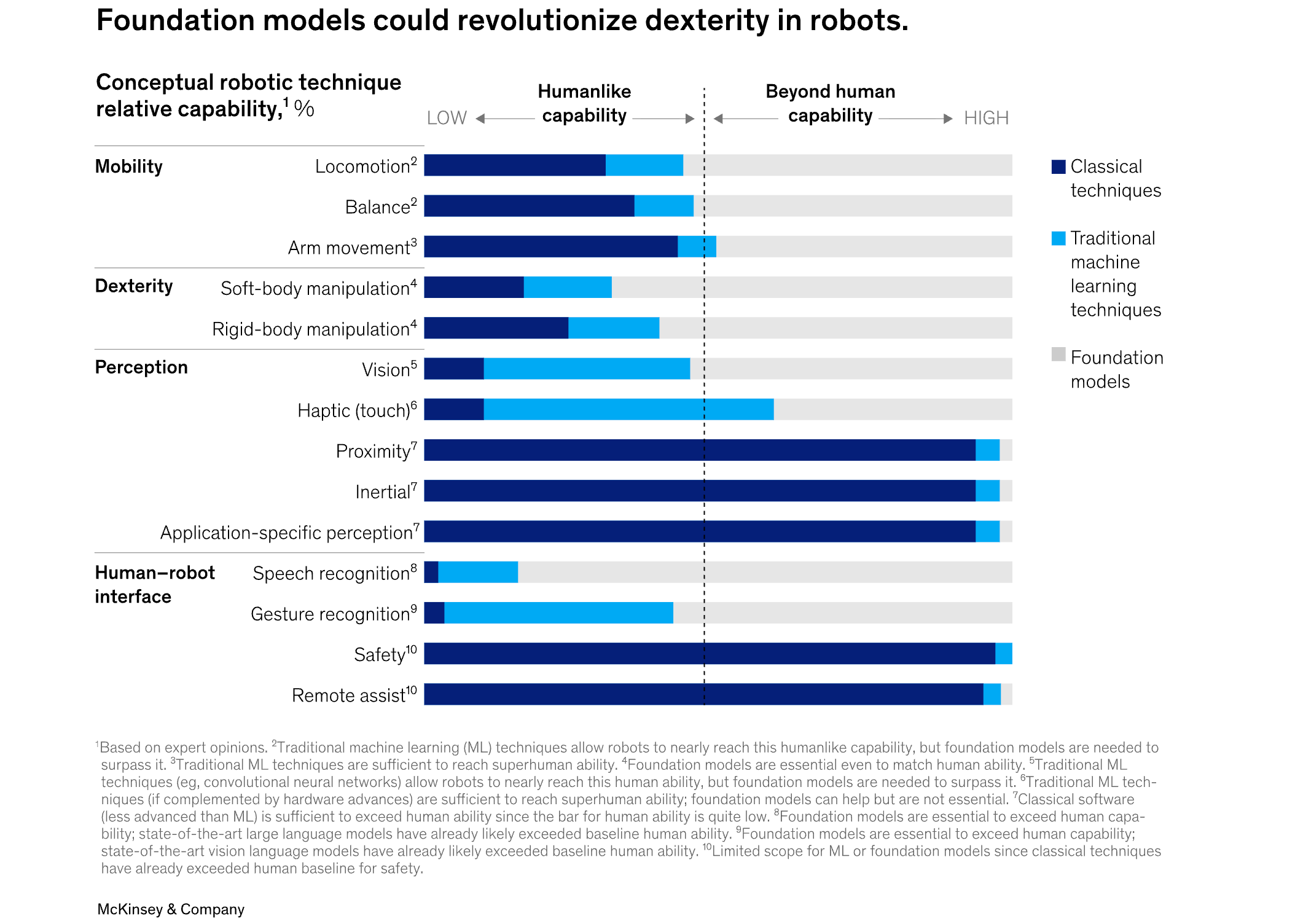
This technological leap is not happening in a vacuum. It is converging with powerful demographic tailwinds—aging populations and looming structural labor shortages—that create an enormous economic pull for this new wave of automation.
The potential scale is staggering. Projections from Morgan Stanley suggest a future where tens of millions of humanoid robots could be integrated into the U.S. economy by 2050, representing a multi-trillion-dollar shift in the labor market.
This powerful convergence of AI, robotics, and demographics is a topic that warrants its own deep dive, which I will explore in an upcoming analysis.