Emergent Reality Simulation with OpenAI Sora Text-to-Video
OpenAI's Sora has the ability to create worlds that appear and act in a manner virtually identical to the real world. Behind the amazing visuals, is a nascent capability to simulate reality.

Looking past the amazing visuals Sora teased us with earlier this week, there is a ground breaking, nascent, capability to simulate reality. Objects interact as they should in the physical world, meaning Sora has a generalized understanding of some aspects of how the world works. It's not yet perfect, but it does offer a tantalizing preview of what is to come.
Generated with Sora
Why This is Such a Big Deal
Prior to generative AI, computer imagery required recreating the world through 3D modeling. This is an extremely labor intensive process as each object in a scene must be placed there by an artist, and is computationally intensive because the behavior of light and fluids needs to be brute-forced calculated by the computer.
Sora does not use fluid dynamics to simulate waves, or use ray-tracing to simulate light refraction. It understands those things intuitively to create beautiful scenes.
Generated with Sora
Computer generated graphics never seemed to quite match reality, leading to the uncanny valley effect when trying to recreate human faces. Sora-generated faces are indistinguishable from reality.
Generated with Sora
Combining Diffusion and Transformers
Prior to Sora, image and video generation AI models relied almost exclusively on a process called diffusion. The algorithm starts with a random noise image and then, through a series of learned steps, gradually removes the noise while adding details to transform this noise into a coherent image that matches a given prompt or specification. This approach has proven to be remarkably effective for generating high-quality images and very short video clips, with little movement.
Sora diverges from traditional approaches by its ability to generate high-fidelity videos of up to a minute in duration, across various durations, resolutions, and aspect ratios.
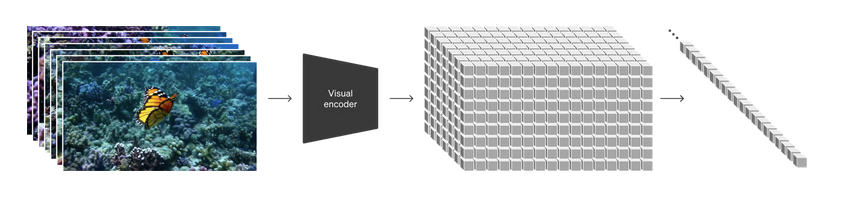
Sora combines the diffusion architecture from image generation models with a transformer architecture of large language models. In an LLM, text is represented as chunks called tokens. In Sora, visual data is broken up in to spacetime segments called patches. However, Sora doesn't create videos by guessing what comes next frame by frame. Instead, it works in a latest space of these abstract sketches (patches) to plan out the video and then translates that plan into the actual video frames. Working in latent space lets Sora plan better because it is not bogged down by the details from the start.
Sora also uses highly descriptive synthetic text captioning of each frame to help maintain long-range coherence and temporal consistency to its subjects.
Generated with Sora
Limitations
Sora's understanding of physics is fragile. While it does mostly exhibit object permanence, it doesn't fully grasp cause and effect, leading to some reality bending visuals as seen below.
Generated with Sora
It also struggles with some specific interactions, like glass shattering.
Generated with Sora
The Future
These are early first steps, think of this as a GPT2 or GPT3, but you can already begin to extrapolate what Sora will be capable of once it achieves GPT4 levels.


