The Rise of Modular AI Models
Combining the strengths of multiple expert AI models to solve a problem is yielding promising results. We look at how the latest open Mixtral 8x7B model challenges GPT-3.5 at a fraction of the size.


Fusing multiple models is a promising direction in AI research. It has the potential to enable new cognitive architectures with reusable, specialized modules (e.g., a sentiment module, a fact-check module or a high-level planning module) and even allow AI models to learn continuously without costly retraining.
Crucially, training small models individually is significantly faster and cheaper compared to the 50B+ parameter behemoths from the handful of companies with resources to train them.
It remains an open question exactly how much parameter quantity affects the emergent behaviors within AI models, such as the ability to generalize. (The Unpredictable Abilities Emerging from Large AI Models). Recent research in training techniques however, shows that small models can be very capable in specific domains (Phi-2: The surprising power of small language models).
In late 2023, Mistral AI took an entirely different approach to model architecture when they released Mixtral 8x7B. Not only does it outperform existing models like GPT-3.5 and Llama 2 in many tasks, but it does it with a fraction of computing resources - it can run on a laptop.
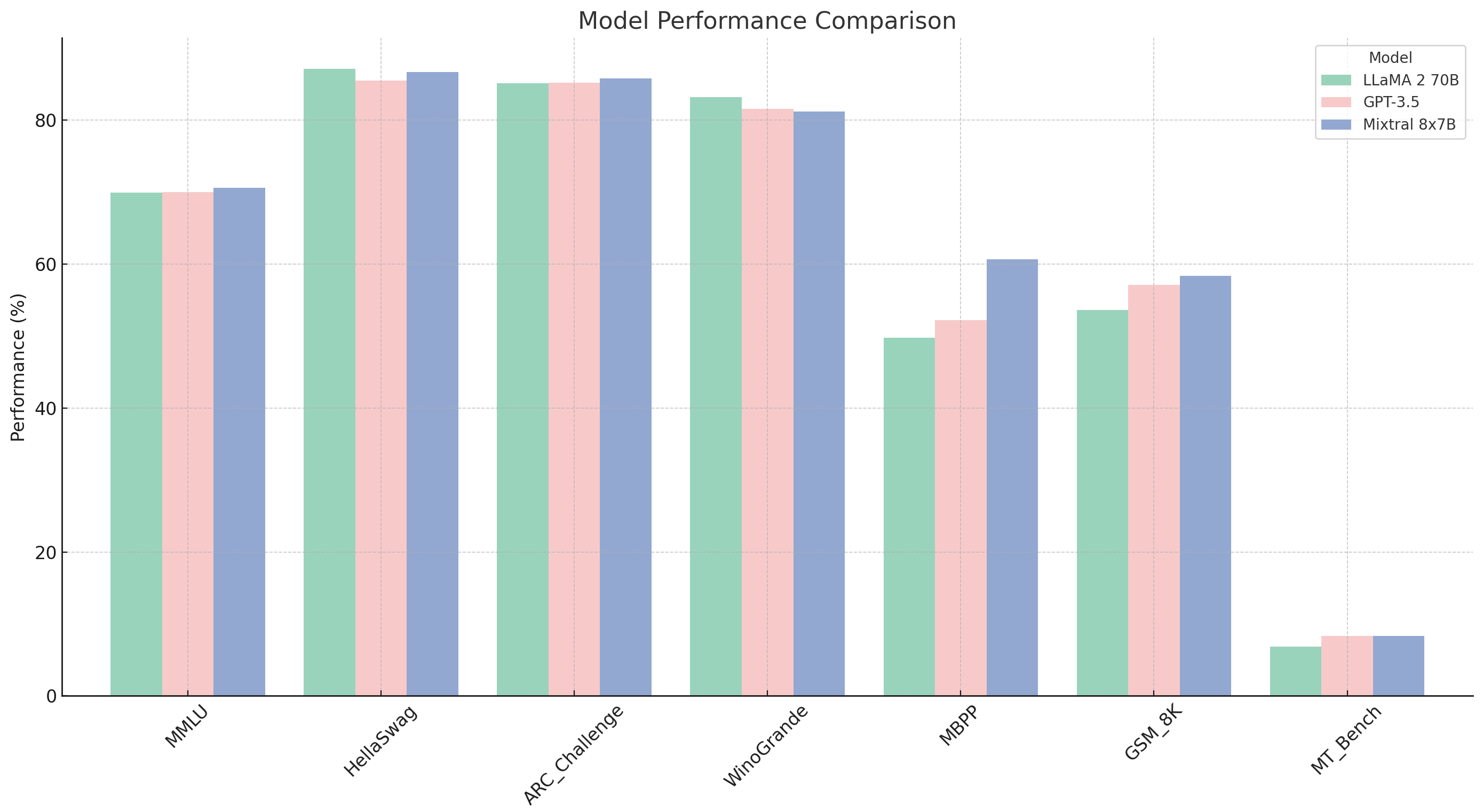
Mixtral 8x7B takes advantage of an architecture paradigm called Mixture of Experts (MoE). Initially proposed in 1994, this architecture is not new, but it has not been widely used within the generative AI space.
Note: Although little is published about OpenAI's GPT4 architecture, it is thought to be comprised of 8 220B expert models trained with different tasks and data.
How Mixtral's MoE works

- When a router receives an input token it decides which two out of eight experts should handle it.
- The routing appears to be based on text syntax within Mistral, but in other implementations of MoE, the experts are trained in different domains (Beyonder-4x7B-v2 combines chat, code, math and a role playing models).
- The final output is a combination of outputs from the two experts, weighted by how much the router trusts each expert for that particular input.
Efficiency improvements
In a traditional AI model, all "neurons" participate in processing every single token. This is not only compute intensive, but it also requires large amounts of memory. MoE's parallel architecture is much more efficient, only requiring a small part of the model to be engaged at a time. Within Mixtral, while each token has access to 47B parameters, only 13B are needed for processing.
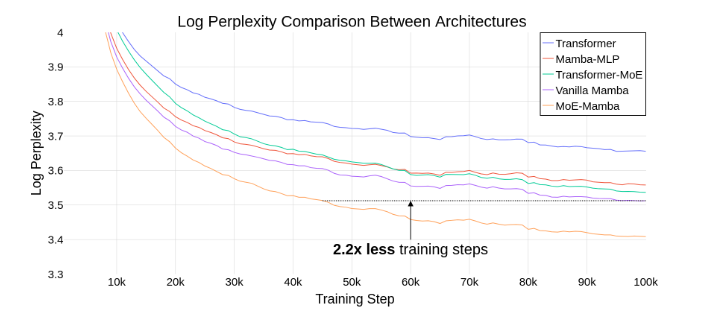
MoE models are also much faster to train. In one paper, MoE model was able to achieve the same performance as a traditional model in 2.2x less training steps.
A promising future
Mixtral is a step in a new direction, and a reminder that we are still very early in our AI journey. New cognitive architectures will certainly continue to emerge based on this and other concepts, perhaps hierarchically linking different models for planning and execution, or mixing different paradigms altogether such as adding Symbolic AI (traditional AI that excels at logic and games) as one of the experts.
Combining smaller models so that the whole is greater than the sum of its parts has potential to shift power away from big AI players such as OpenAI and Google. While monolithic models crafted by these powerhouses will shift further to consumer applications, modular and open-source AI models will likely continue to be at the center of innovation.
For now, you can try Mixtral for yourself:

Sources: