Chain-of-Thought Reasoning Without Prompting
Google DeepMind proposes a new method to induce reasoning in AI without complex prompt engineering.


The Google DeepMind paper titled "Chain-of-Thought Reasoning Without Prompting" introduces a new method for drawing out the reasoning process from large language models (LLMs) without the need for complex prompting strategies like few-shot or zero-shot. Typically, guiding LLMs to reach their conclusions requires intricate prompt design, which might not work well for every type of task. However, this study suggests a simpler, more universal approach.
The key innovation here is a tweak in the decoding process, which is the method by which the model selects the next word in a sequence. Instead of sticking to the most likely next word (a common method known as greedy decoding), this approach explores various alternatives at each step. Surprisingly, these alternative paths often naturally reveal a chain of thought (CoT) reasoning process, even without direct prompts asking the model to show its work.
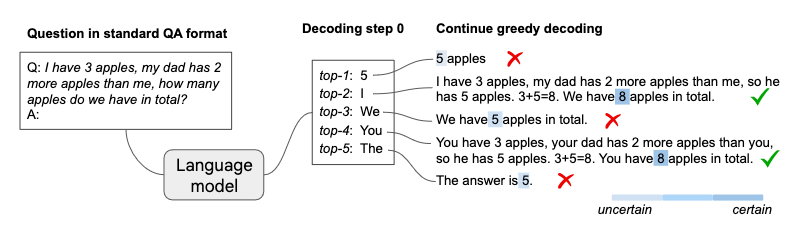
To sift through these alternative decoding paths and find the most reliable reasoning processes, the researchers introduced a confidence score. This score helps identify which CoT paths are most likely to lead to accurate conclusions.
The researchers tested this new CoT-decoding method across different types of reasoning tasks, including math problems, commonsense questions, and symbolic reasoning challenges. The results were impressive: CoT-decoding not only outperformed the traditional greedy decoding method but also matched, and in some cases approached, the effectiveness of the more complex prompted approaches, without requiring any of the prompt engineering usually necessary.
Further analysis showed that the presence of CoT reasoning correlated with the model's confidence in its answers. This suggests that when LLMs can work through a problem step-by-step, they're more sure of their final response.
Interestingly, the study also found that CoT reasoning was more commonly found in tasks that the models encountered frequently, compared to more complex, synthetic tasks. This indicates that the models are learning from experience, developing reasoning pathways for problems they see more often.
This research demonstrates that LLMs have an intrinsic ability to reason through problems in a step-by-step manner, a capability that goes beyond what is typically revealed through greedy decoding. By simply changing the decoding strategy, it's possible to uncover this inherent reasoning ability without needing to craft specific prompts. This discovery opens up new avenues for understanding and leveraging the built-in reasoning capacities of pre-trained LLMs, offering a simpler method to explore how these models think and solve problems.