AI Reasoning, Inference-Time Scaling and DeepSeek R1
How do we teach machines to truly think? Recent breakthroughs in AI reasoning - exemplified by DeepSeek R1 and OpenAI's o1 - show how models can now tackle complex problems through step-by-step deliberation. Explore how this cognitive shift is transforming the future of artificial intelligence.


The development of enhanced reasoning capabilities has become a central focus in AI research, marked by notable advancements in recent months. DeepSeek R1 represents a significant milestone in this field, demonstrating reasoning abilities that match those of OpenAI's latest models.
Thinking Fast and Slow
Drawing from psychologist Daniel Kahneman's cognitive framework, we can understand the challenge of AI reasoning through the lens of System 1 and System 2 thinking.
In human cognition, these two modes run in parallel. System 1 runs automatically—like when you recognize a friend's face or know to brake at a red light. It's quick, effortless, and shaped by experience.
System 2 kicks in for harder tasks, like solving a complex math problem or weighing pros and cons of a major decision. This deliberate thinking demands focus and mental energy.
| System 1 (Fast Thinking) | System 2 (Slow Thinking) |
|---|---|
| Fast, automatic, immediate | Slow, deliberate, methodical |
| Unconscious, operates below awareness | Conscious, involves active reasoning and awareness |
| Error prone. Prone to biases and systematic errors | Reliable. Can detect and correct errors when sufficient attention is applied |
Auto-regressive LLMs such as GPT-4 can be considered System 1 thinkers. They statistically predict the next best token, and lack central planing to solve complex problems.

In order to solve complex problems, machines need to "think" in steps, evaluate multiple approaches, then weigh them by evaluating and validate them.
Inference-Time Scaling
Inference-Time Scaling is a growing trend in AI that tackles System 2 thinking. Instead of generating the answer in one swift pass, the model generates multiple answer “drafts" and reviews them before settling on a final result. This approach is also known as Chain-of-Thought or CoT.
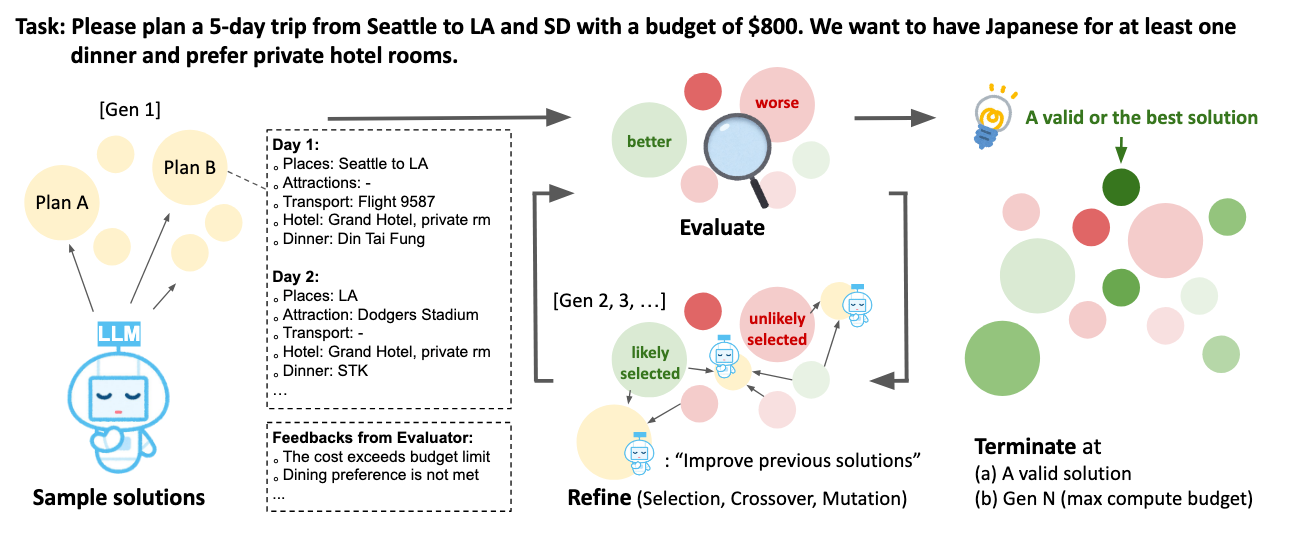
Modern AI reasoning models, such as OpenAI's o1 and now DeepSeek R1 use CoT to break down their thinking into explicit steps before generating a final answer. Think of it like showing your work in a math problem – the model creates hidden steps to work through its logic and consider different approaches before arriving at its conclusion. This internal deliberation process significantly enhances the model's ability to handle complex problems and produce well-reasoned answers.
The number of internal reasoning tokens can far exceed the tokens needed to output the result. There appears to be a strong correlation between the number of intermediate tokens used and the sophistication of the model's response. This explains why o1, which uses extensive internal reasoning, can generate higher quality answers than GPT-4, but comes with higher computational costs due to the additional processing required for these internal steps.
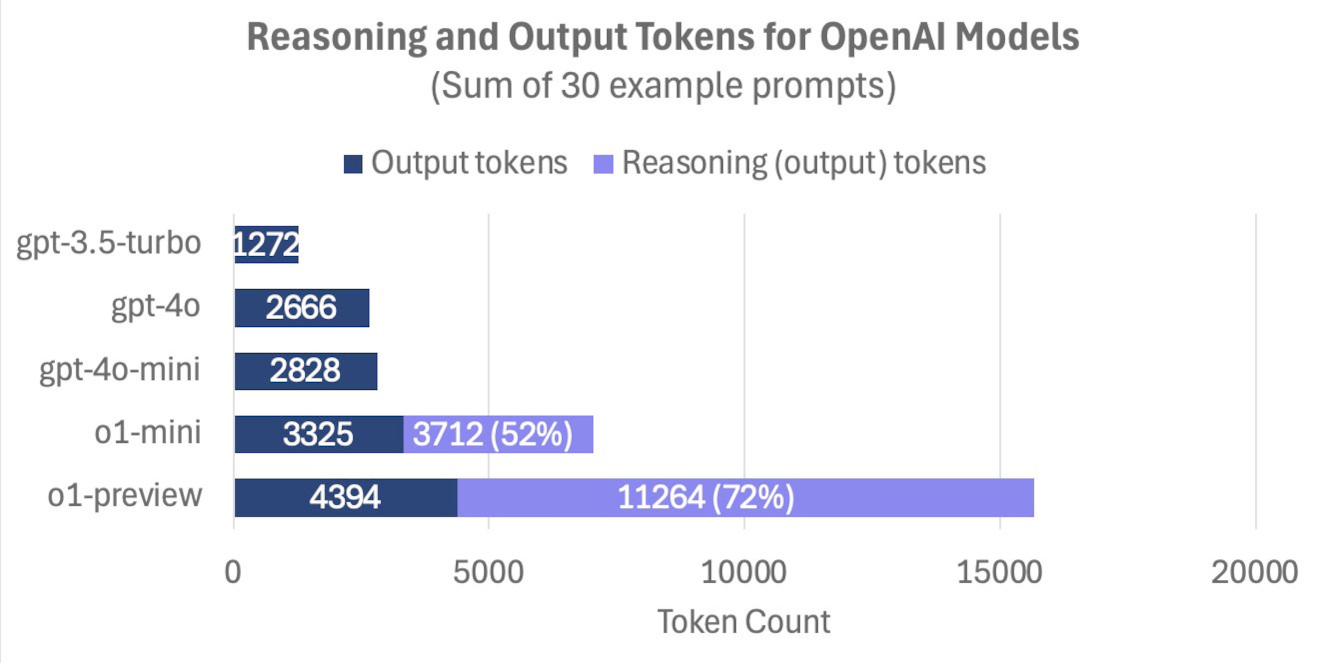
The ChatGPT o1 Pro model at $200/month is basically the same model as the base $20/month ChaptGPT o1, the difference is that o1 Pro thinks for a lot longer before responding, generating more reasoning tokens, and consuming a larger amount of inference compute for every response.
Importantly, this extra “mental” effort can transform smaller models into contenders that rival or even outperform their larger (and more expensive) counterparts.
DeepSeek R1
In early 2025, a group of Chinese researches have released DeepSeek R1, an open source reasoning model that rivals in performance to o1.
While OpenAI maintains strict secrecy around o1's internal workings, DeepSeek R1 offers total transparency by displaying its reasoning process through intermediate tokens.
The group that produced DeekSeek R1 has not only published the model for download (https://github.com/deepseek-ai/DeepSeek-R1), but also has been very open in explaining how it works (https://arxiv.org/abs/2501.12948).
Interestingly, according to the paper, R1 developed a number of emergent properties that it wasn't explicitly programmed to have:
- Thinking longer on complex problems. R1 allocates additional processing time to more complex problems by prioritizing tasks based on their difficulty.
- Reflection. R1 revisits and reevaluates its previous steps.
- Alternatives. R1 explores alternative approaches.
These characteristics closely mirror System 2 thinking – the deliberate, analytical mode of human cognition – and it's intriguing that such patterns emerged naturally within R1.
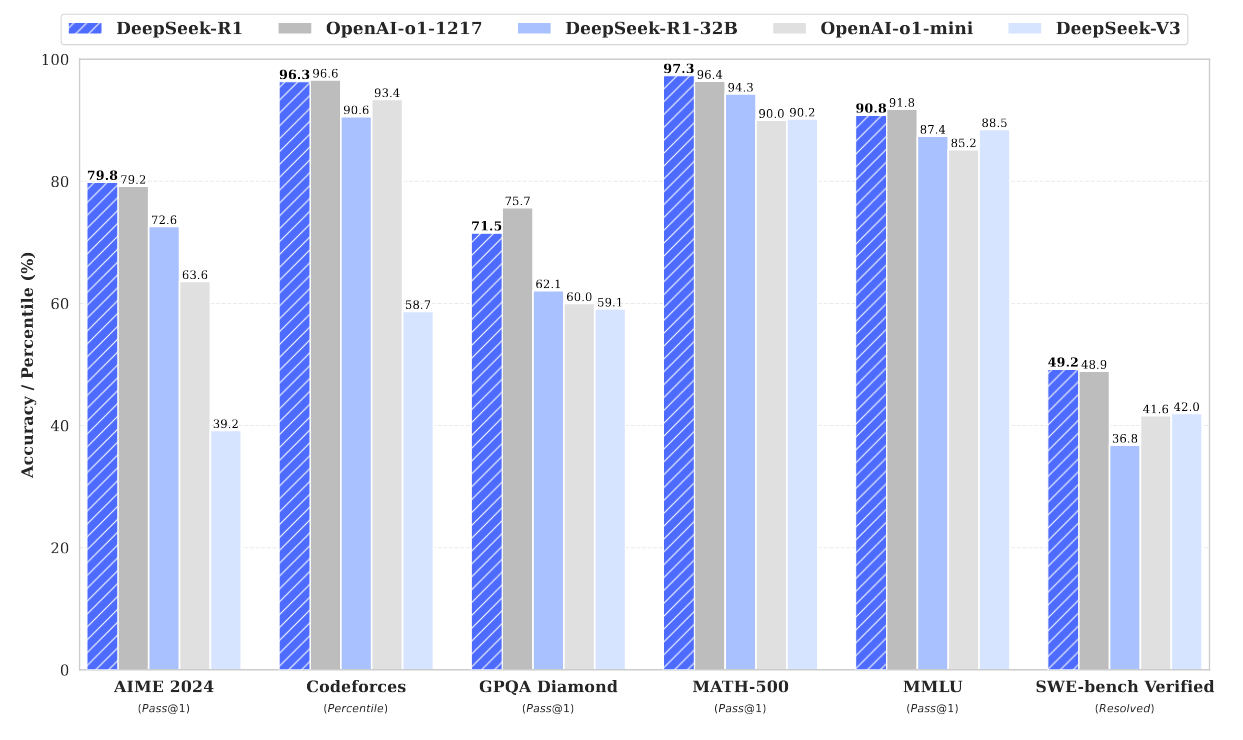
DeepSeek R1 achieves a dual cost advantage over OpenAI's o1 - both in its development costs and operational expenses for generating responses. Since the longer reasoning models think, the better they perform, this is a significant development towards creating more advanced AI systems.
| Feature | Deepseek R1 | OpenAI o1 |
|---|---|---|
| Training Approach | Reinforcement learning with minimal supervised data | Supervised fine-tuning (SFT) with RLHF |
| Input Token Cost | $0.14 (cached), $0.55 (non-cached) per million tokens | $7.50 (cached), $15.00 (non-cached) per million tokens |
| Output Token Cost | $2.19 per million tokens | $60 per million tokens 27x more expensive than R1 |
| Codeforce Benchmark | 96.3 (Percentile) | 96.6 (Percentile) |
| Math Benchmark | 79.8 – AIME 2024 97.3 – MATH 500 |
79.2 – AIME 2024 96.4 – MATH 500 |
Geopolitics and CapEx
Access to computational power has emerged as a strategic geopolitical lever. The strategy assumes that by restricting China's access to advanced computing capabilities, the US can maintain its lead in artificial intelligence development.
DeepSeek R1's development reveals a significant weakness in this strategy. Despite facing strict export controls, the Chinese company created R1 in just two months with a modest $6 million investment, achieving performance comparable to o1.
This not only casts doubt on the effectiveness of AI-related export controls, but also challenges the massive capital expenditure figures that OpenAI and Meta claim are necessary to maintain AI leadership.
Conclusion
The emergence of these reasoning models marks a crucial shift in AI development. The next frontier in artificial intelligence isn't just about making models bigger—it's about making them think better. As systems learn to think deliberately rather than just pattern-match, we're moving closer to AI that can tackle increasingly complex cognitive tasks with human-like deliberation. These developments also force us to reconsider our traditional assumptions about the computational requirements for both training and running AI models.